Dispatch
Your Content Workflow Is Already Obsolete. Your AI Agent Is the Replacement.
AI in content marketing is table stakes; most workflows using it aren't fast or flexible enough to keep up. A better option: stop treating AI as a feature bolted onto your workflow and start treating the agent as the workflow — so the workflow itself evolves, fast, without a vendor release cycle or a team meeting. Here's how and why I built an editorial calendar on top of a coding agent with Markdown files and a weekend of work.

AI in content marketing isn’t an advantage anymore. It’s table stakes. If your workflow doesn’t have AI somewhere in the loop — drafting, rewriting, analyzing, distributing — you’re already losing to the operations that do. That should, I hope, be obvious by now.
What’s less obvious: most of the workflows that do have AI in them aren’t fast or flexible enough to keep up. I’ve lived through two common failure modes — and, I hope, out the other side of both.
Unsustainable Approach #1: the homegrown process. A loose pile of Google Docs, Slack approvals, and spreadsheets, with ChatGPT open in a browser tab for the parts that feel AI-shaped. Someone has to remember to update the tracker. Someone compiles analytics by hand. When the process changes, the change lives in someone’s head until they write it down somewhere, and they never quite do. It’s flexible in the sense that it could go anywhere — but it doesn’t reliably go anywhere, because it depends on everyone remembering and faithfully acting on the same (probably unwritten) rules.
Unsustainable Approach #2: the SaaS stack. Some features are AI-powered, but the workflow shape is whatever your vendor decided on last quarter. Every generic editorial-calendar tool has an opinion about what “a post” is, and some of those opinions don’t match yours. You keep a second informal system on the side because the tool can’t hold half of what your actual workflow needs. The integrations you’d actually use — your analytics, the social platform of the week, a new content format — aren’t on anyone’s roadmap this quarter.
Both failures are stuck on the same structural issue: a process that isn’t clear, isn’t low-friction, isn’t repeatable, and doesn’t improve itself between posts. Adding more people or more tools doesn’t address the shape.
There’s another option that didn’t really exist eighteen months ago. Stop treating the AI as a feature bolted onto your workflow, and start treating the agent as the workflow. You never leave the agent for a static tool. You talk to it. It does the work. Over time, it accumulates a toolkit of its own — shortcuts, scripts, conventions — and refines that toolkit through use. Skills that don’t carry their weight get rewritten or thrown out. Skills that work get sharpened. The agent’s toolkit isn’t a static configuration you set up once; it evolves, under your direction, in response to what the work actually needs. Claude Code, Codex, Cursor, any of the serious coding agents shipped in the last year will do this. The agent is the closest thing most content teams have ever had to a full-time in-house developer, and the cost of having one is no longer the limiting factor.
Friction is the thing the agent model is actually attacking, and it’s the one measure neither vendor pricing nor headcount captures.
This post is about what that looks like in practice, using the editorial calendar I built for audiocontrol.org (and, now, editorialcontrol.org) as the example.
What it looks like when the agent is the workflow
There is no editorial calendar app. There is no hosted dashboard. There is a conversation with Claude Code and a Markdown file in the repo (docs/editorial-calendar.md) that the agent reads and updates as work happens.
(In the days after this piece went to press, two local review surfaces accreted on top of that file — an Editorial Studio page that renders the calendar as actionable rows, and a margin-note Review UI for iterating on drafts side-by-side with the agent. Neither is a SaaS product. Both run under the same dev server used for the website, against the same Markdown on disk. The backend is still the agent.)
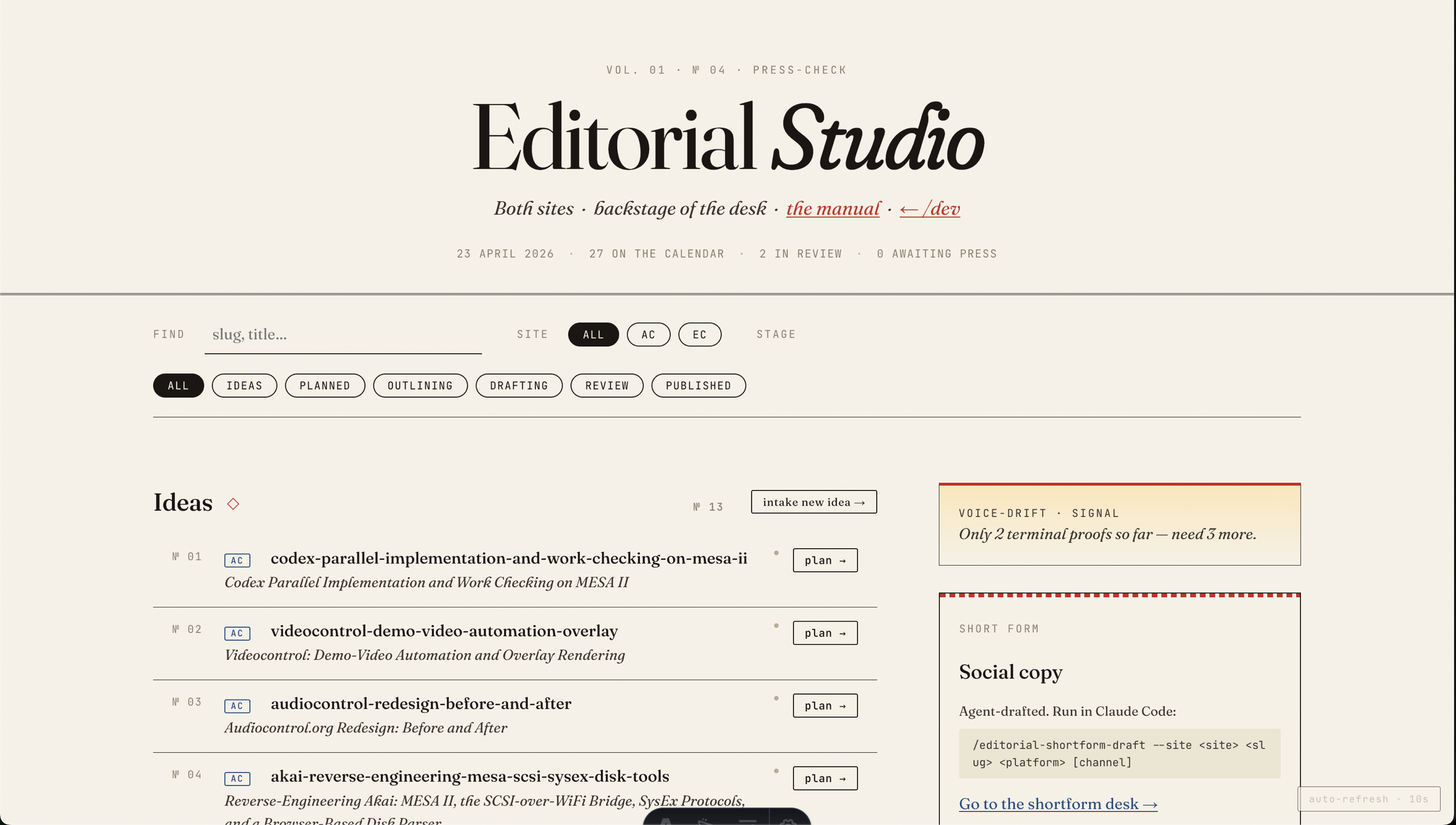

The file has one section per stage of the content lifecycle: Ideas, Planned, Outlining, Drafting, Review, Published, plus a Distribution section tracking where each published post has been shared. Each stage is a pipe-delimited Markdown table. Readable by a human, parseable by a script. No database. No login screen. git log is the audit trail. grep is the search.
From the outside — from the seat of the person doing the work — none of that file structure matters. The interaction is: “add an idea for a post about MESA II loop-point detection” or “what should I write next?” or “publish the agent-workflow post.” The agent handles the rest.
What the agent reaches for, behind the scenes, is a set of skills it has accumulated over the life of the project. In Claude Code these live in .claude/skills/ as short Markdown files. Each codifies one action the agent has learned to do reliably:
/editorial-add "Title"— capture an idea in the Ideas stage/editorial-plan <slug>— move Ideas → Planned, set target keywords and topic tags/editorial-draft <slug>— scaffold the blog post directory, create a GitHub tracking issue, move to Drafting/editorial-publish <slug>— move to Published, close the issue/editorial-distribute— record a share on Reddit, YouTube, LinkedIn, or Instagram/editorial-reddit-sync— pull your own Reddit submissions via the public API, attribute each to the right post or video automatically/editorial-reddit-opportunities <slug>— list subreddits a post hasn’t been shared to yet, enriched with live subscriber counts/editorial-suggest— pull Search Console data and propose new topics from striking-distance queries and CTR opportunities/editorial-performance— per-post analytics rollup across Umami, GA4, and Search Console, with update recommendations/editorial-cross-link-review— audit bidirectional linking between blog posts, YouTube videos, and tools on the site
These aren’t a product surface. They’re the agent’s habits — the things it knows how to do without being re-explained. The set isn’t fixed. New patterns in the work produce new skills. Skills that turn out to be wrong, or clumsy, or duplicative get rewritten or retired. It’s artificial selection applied to workflow: the skills that make the operation faster survive; the ones that don’t, don’t. Over enough cycles, what’s left is a toolkit shaped specifically to how you work — and it keeps getting shaped, because the selection pressure never stops.
The .claude/skills/ convention is Claude Code-specific. Cursor has its own equivalent convention. Every serious agent has an equivalent. The substance transfers, even if the filename doesn’t. And, it’s trivial to get an agent to port the skill set from one agent to another.
Flexibility as survival
The clearest case for the agent-as-workflow model is the changes that had to happen mid-operation. Four representative moves from the first eight days of this project’s history (first calendar commit: 2026-04-15), each of which would have required a SaaS vendor feature request or a homegrown-process rebellion:
Adding YouTube as a first-class content type. A Reddit sync surfaced six recent shares of a YouTube demo video — not a blog post. The calendar had no place to track that. I asked the agent to make YouTube a first-class entry type alongside blog posts. It figured out what that meant and made it so: the schema shift, the parser update, the skill branches, the re-sync. I reviewed the diff, said yes, and the six previously-unattributable shares attached to the right entry. Time elapsed: an afternoon. I never opened the code.
Adding a tool content type for standalone apps. Two other Reddit posts linked to a web-based editor hosted on the same site — not a blog post, not a video, just an app at a URL. Same kind of change: extend the content type to 'blog' | 'youtube' | 'tool', add the lifecycle branch, re-run the sync. Afternoon. No vendor involved.
Adding new subreddit topics as audience targeting sharpened. content-marketing and automation-workflow didn’t exist as tags on this project a week ago. Editing one JSON file added them, along with curated subreddit lists for each. The cross-posting skill picked them up on next run. Zero lines of product code.
Breaking out a sibling publication in an evening. Around day four of this project, it became clear that the posts being drafted fell into two different registers — hardware service-manual work for musicians on one side, meta-commentary on using AI to build (and write about) that work on the other. They didn’t belong on the same site. So editorialcontrol.org, the publication you’re reading now, got spun up in a single evening: voice definition, design, a per-site content-collection split, new shared nav, the existing multi-site infrastructure already in place to absorb it. Nobody filed a product-expansion ticket. No roadmap consultation. The old site kept its register; this one got its own.
Then there’s the case that isn’t a bullet. A sibling system in the same repo — a feature-image pipeline — started generating branded AI images for posts. Wiring it into the editorial calendar took about as long as writing this sentence: one new field on the entry schema (contentUrl), a new skill family (/feature-image-*) that reads from and writes to the calendar, and done. Nobody filed a support ticket. Nobody waited for a release. The post you’re reading right now will get its feature image through that pipeline in the next session, because there’s nothing in the way of making that happen.
None of these changes were on anyone’s product roadmap. None of them took more than a day. All of them took the shape they did because the agent already had the context to make them — and the changes themselves became new habits the agent kept afterward.
Speed compounds
The less-visible argument for agent-as-workflow is the feedback loop. Two of them, actually.
The content loop. Automation drops the fixed cost per post: no hand-cropping feature images, no manual distribution tracking, no cross-link auditing by eyeball and sheer willpower. Once the per-post cost is close to zero, the threshold for “worth shipping” drops with it. A small observation, a one-paragraph idea, a niche angle you’d have hesitated to commit a weekend to: all of those become postable. More posts shipped means more analytics data, which means /editorial-suggest — part of a broader analytics-automation skill family this publication will have its own dispatch on shortly — surfaces more specific opportunities. A query at position 14 with 200 monthly impressions is a real signal; a query with 5 isn’t. More specific suggestions sharpen the next batch of posts. The posts produce their own data. The agent learns from content.
The effect is structural, not anecdotal: once the per-post cost drops far enough, the threshold for shipping drops with it. The tooling started earning its keep in the first weeks; the numbers worth quoting come later, once there’s a longer track record behind them.
The skills loop. The skills themselves are also under selection pressure. /editorial-reddit-sync has been rewritten twice and extended a third time since it first shipped — once because an OAuth-based auth scheme was too much setup friction to live with, once when YouTube shares exposed the need to match video URLs in addition to blog URLs, and again when tool joined blog and youtube as a valid content type. /editorial-cross-link-review started out auditing only blog-to-YouTube links; when it became clear that tool pages on the site were their own category of link target, it grew to fetch and parse their HTML. Skills that stopped earning their place get folded into others or retired. The toolkit on disk today is not the toolkit from two months ago, and it won’t be the toolkit two months from now.
This is the part that a SaaS stack can’t replicate and a homegrown process can’t sustain: the workflow itself is evolving, fast, without a vendor release cycle or a team meeting.
Both loops only work if friction stays low. SaaS friction, even a few minutes of it compounded across every post, breaks them. Homegrown-process friction breaks them the same way, with different stalls. And friction — as noted up top — is the measure that neither vendor pricing nor headcount captures.
If you’re still reading, here’s the short version
- Pick an agent you already use. Claude Code, Codex, Cursor, Windsurf, Amp — the workflow maps to any of them.
- Keep the calendar in one Markdown file, versioned in git. One table per stage. Hand-editable in any text editor; machine-parseable in twenty lines of code. The agent reads and writes it directly.
- Write each action as a skill. The convention depends on the agent; the substance is the same — a short Markdown file telling the agent what the action does and how to do it reliably, referring to library functions for the mechanical parts. Expect to rewrite it. Skills that don’t carry their weight should get refactored or deleted; the toolkit is supposed to evolve.
- One skill per action, UNIX-style.
/editorial-add,/editorial-plan,/editorial-draft. Composable beats monolithic.
Nothing on that list requires a specialized tool. It requires a repo, an agent, and a willingness to stop treating workflow shape as someone else’s problem.
Where this is going
The post you’re reading right now was made through the exact setup it describes. It was captured through a conversation that triggered /editorial-add, planned through one that triggered /editorial-plan, drafted through /editorial-draft, and published through /editorial-publish. The draft was iterated on in the same conversation with the same agent. The cross-link audit will flag this post’s outbound links within an hour of shipping. No other interface was opened to make any of that happen.
If you want help building this for your own operation, get in touch.
Otherwise: the agent got out of the way, so the content got made.